Тестирование модели NLU#
- Определение
- Метрики для оценки классификации намерений
- Метрики для оценки извлечения сущностей
- Ручная оценка намерений
- Автоматизированная оценка намерений и сущностей
- Отчеты об оценке
Определение#
Тестирование модели NLU — это процесс проверки того, насколько точно модель NLU извлекает намерения и сущности из сообщений пользователя. Это важная часть разработки бота, так как от точности распознавания намерений зависит, насколько корректно бот сможет реагировать на запросы пользователя.
Метрики для оценки классификации намерений#
-
Точность (Precision)
Точность показывает, какую долю предсказанных намерений модель определила верно, исключая ложные срабатывания (False Positives). Precision отвечает на вопрос "Сколько из всех предсказанных моделью намерений X были действительно правильными?".
Формула:
\[ \text{Precision} = \frac{\text{True Positives (TP)}}{\text{True Positives (TP)} + \text{False Positives (FP)}} \]Где:
- True Positives (TP): Количество примеров, где модель правильно предсказала намерение.
- False Positives (FP): Количество примеров, где модель ошибочно предсказала намерение (ложные срабатывания).
-
Доля правильных предсказаний (Accuracy)
Доля правильных предсказаний — это доля правильно классифицированных примеров относительно общего числа примеров. Она отвечает на вопрос: "Сколько из всех примеров модель предсказала правильно?".
Формула:
\[ \text{Доля правильных предсказаний} = \frac{\text{Количество правильных предсказаний}}{\text{Общее количество примеров}} \] -
Полнота (Recall)
Полнота — это метрика, которая показывает, какую долю реальных примеров определенного намерения модель смогла правильно распознать. Другими словами, она отвечает на вопрос: "Сколько из всех реальных примеров намерения X модель правильно предсказала?".
Формула:
\[ \text{Полнота} = \frac{\text{True Positives (TP)}}{\text{True Positives (TP)} + \text{False Negatives (FN)}} \]Где:
- True Positives (TP): Количество примеров, где модель правильно предсказала намерение.
- False Negatives (FP): Количество примеров, где модель не смогла распознать намерение (ошибка пропуска).
-
F1-оценка (F1-Score)
F1-оценка — это среднее гармоническое между точностью и полнотой. Она позволяет оценить, насколько хорошо модель справляется с классификацией, учитывая как ложные срабатывания (False Positives), так и пропуски (False Negatives).
Формула:
\[ \text{F1-оценка} = 2 \times \frac{\text{Точность (Precision)} \times \text{Полнота (Recall)}}{\text{Точность (Precision)} + \text{Полнота (Recall)}} \]Как интерпретировать F1-оценку?
- F1 = 1: Идеальный результат. Модель не допускает ошибок (нет ложных срабатываний и пропусков).
- F1 = 0: Худший результат. Модель не справляется с классификацией.
- F1 между 0 и 1: Чем ближе к 1, тем лучше качество модели.
Метрики для оценки извлечения сущностей#
-
F1-оценка (F1-Score)
F1 — это среднее гармоническое между точностью и полнотой. Она позволяет оценить, насколько хорошо модель находит и классифицирует сущности.
Формула: Аналогична F1-оценки для намерений.
-
Точность (Precision)
Точность — доля правильно извлеченных сущностей относительно всех извлеченных сущностей
Формула:
\[ \text{Entity Precision} = \frac{\text{Правильно извлеченные сущности}}{\text{Все извлеченные сущности}} \] -
Полнота (Recall)
Полнота — доля правильно извлеченных сущностей относительно всех реальных сущностей в данных.
Формула:
\[ \text{Entity Recall} = \frac{\text{Правильно извлеченные сущности}}{\text{Все реальные сущности}} \]
Ручная оценка намерений#
Намерения создаются и заполняются в разделе NLU → вкладка Обучающие данные→ вкладка Примеры. После заполнения намерений и их значений возможна проверка и оценка их точности вручную.
Введите фразу от имени пользователя, и вы получите оценку в виде вероятности совпадения с одним из созданных намерений. В приведенном примере фраза с вероятностью 99% ассоциируется с намерением Приветствие. Если намерение отсутствует, через это поле можно создать новое и присвоить ему текущую фразу.
🔍 Подробнее в инструкции Добавление намерений.
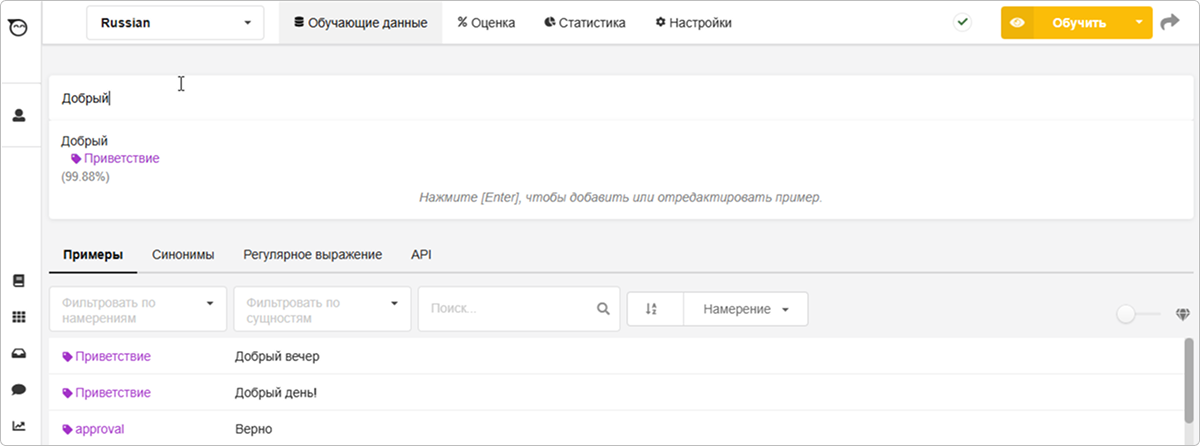
Более развернутую информацию для анализа можно получить на вкладке API. Это можно сделать удаленно с помощью HTTPS-запроса (форма генерируется динамически) при вводе проверяемой фразы. Здесь отображается весь спектр совпадений с существующими намерениями, проранжированных по убыванию вероятности совпадения. Это помогает понять причины неправильных ассоциаций, ведущих к ошибкам в диалогах.
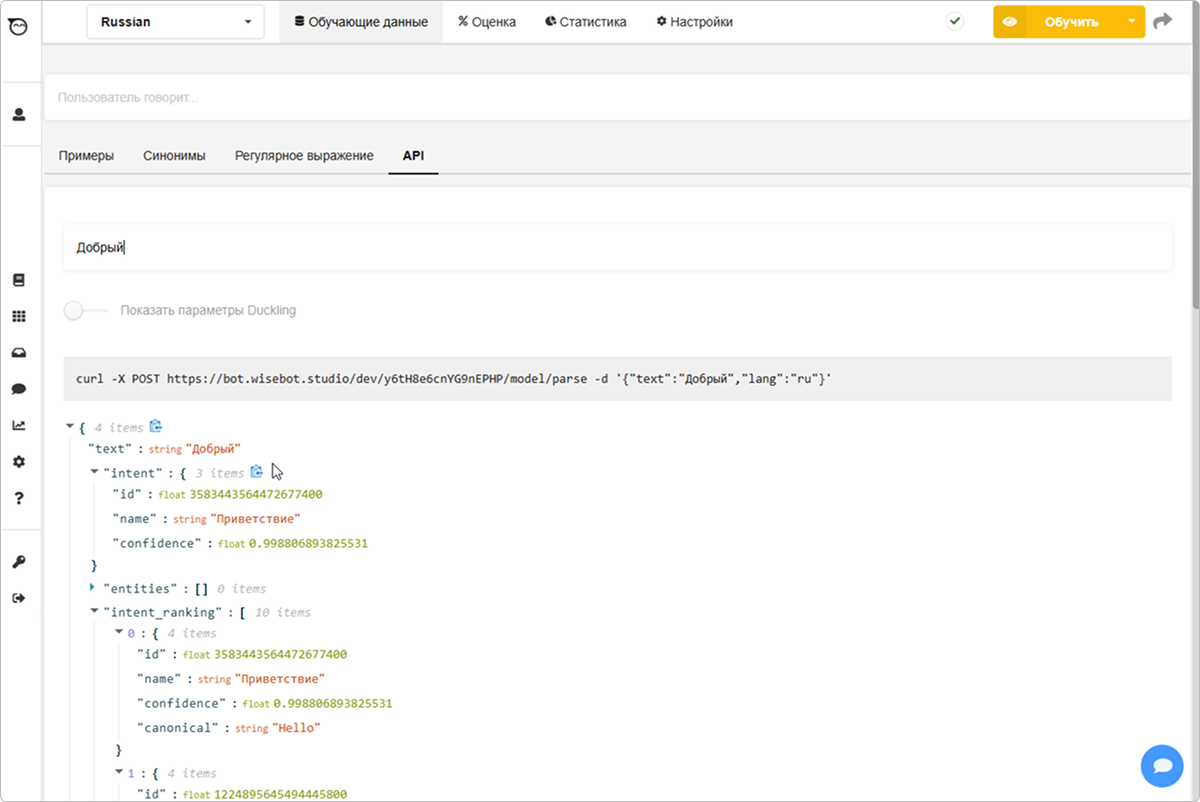
Недостаток данного метода оценки эффективности модели NLU заключается в том, что при большом количестве намерений метод становится трудоемким и не дает ощутимых результатов. Он подходит для разбора исключительных случаев, требующих анализа при явном обнаружении ошибок.
Автоматизированная оценка намерений и сущностей#
Автоматизированная оценка понимания намерений позволяет проверить качество работы NLU-модели с использованием заранее подготовленных тестовых данных.
На вкладке Оценка доступны встроенные инструменты для автоматического тестирования и оценки модели.
Доступны следующие варианты выборки:
- Использовать тренировочный набор. Этот метод особенно полезен на этапе разработки, так как позволяет быстро обнаружить проблемы в проектировании модели или ошибки в аннотации данных. Он включает в себя оценку всех намерений, созданных на вкладке Примеры.
-
Загрузить набор тестов. Позволяет загрузить уже подготовленный набор тестов.
💡 Создание подобного файла рекомендуется выполнять с помощью редактора Chatito. Проект редактора является OpenSource и доступен в репозитории GitHub. Chatito помогает создавать наборы данных для обучения и проверки моделей ассистентов с помощью простого языка разметки DSL. Спецификация языка разметки DSL доступна здесь.
-
Использовать проверенные примеры. Позволяет использовать примеры из реальных диалогов с пользователями. Эти примеры доступны в разделе Входящие и могут быть добавлены в обучающие данные для улучшения модели без ущерба для валидации.
Отчеты об оценке#
Отчеты выводятся в разрезе намерений и сущностей.
Чтобы сформировать отчет об оценке:
-
Настройте один из вариантов выборки:
- Использовать тренировочный набор,
- Загрузить набор тестов**,
- Использовать проверенные примеры.
-
Нажмите Начать оценку.
Дождитесь окончания оценки.
Отчет будет выведен для намерений и сущностей:
-
Намерения
На вкладке Подробный отчет отображается отчет в разрезе метрик.
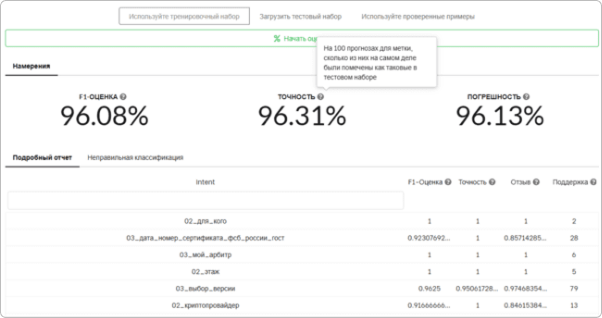
На вкладке Ошибки классификации таблица ошибок для детального анализа.
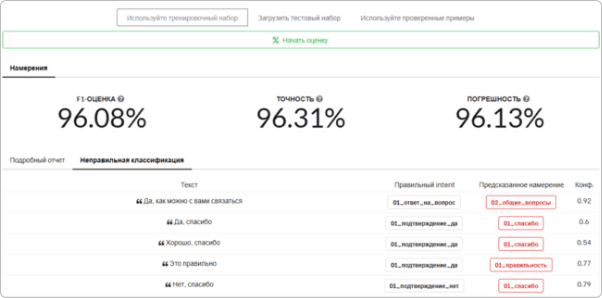
-
Сущности
Для сущностей выводится аналогичный подробный отчет в разрезе метрик.